PrestoDB Explained: High-Performance SQL Query Engine for Big Data Analytics

SHARE THIS ARTICLE
What is Presto?
Presto (or PrestoDB) is a distributed, fast, reliable SQL Query Engine that fetches data from heterogeneous data sources querying large sets((TB, PB) of data and processes in memory. It originated in Facebook as a result of Hive taking a long time to execute queries of TB, and PB magnitude. The problem with Hive was that it would store intermediate results on disk which resulted in a significant I/O overhead on disk. In 2015, Netflix showed PrestoDB was 10 times faster than Hive. Presto is written in Java. It resembles a massively parallel processing (MPP) system that facilitates the separation between storage and computing and allows it to scale its computing power horizontally by adding more servers.
What Presto is Not?
Since Presto understands SQL, it is not a general-purpose relational database. It is not a replacement for MySQL, Oracle, etc., though it provides the features of a standard database. It was not designed to handle OLTP. Its main benefit and value can be seen in Data Warehousing and Analytics where a large volume of data is collected from various sources to produce reports. They fit into the world of OLAP.
Presto Architecture
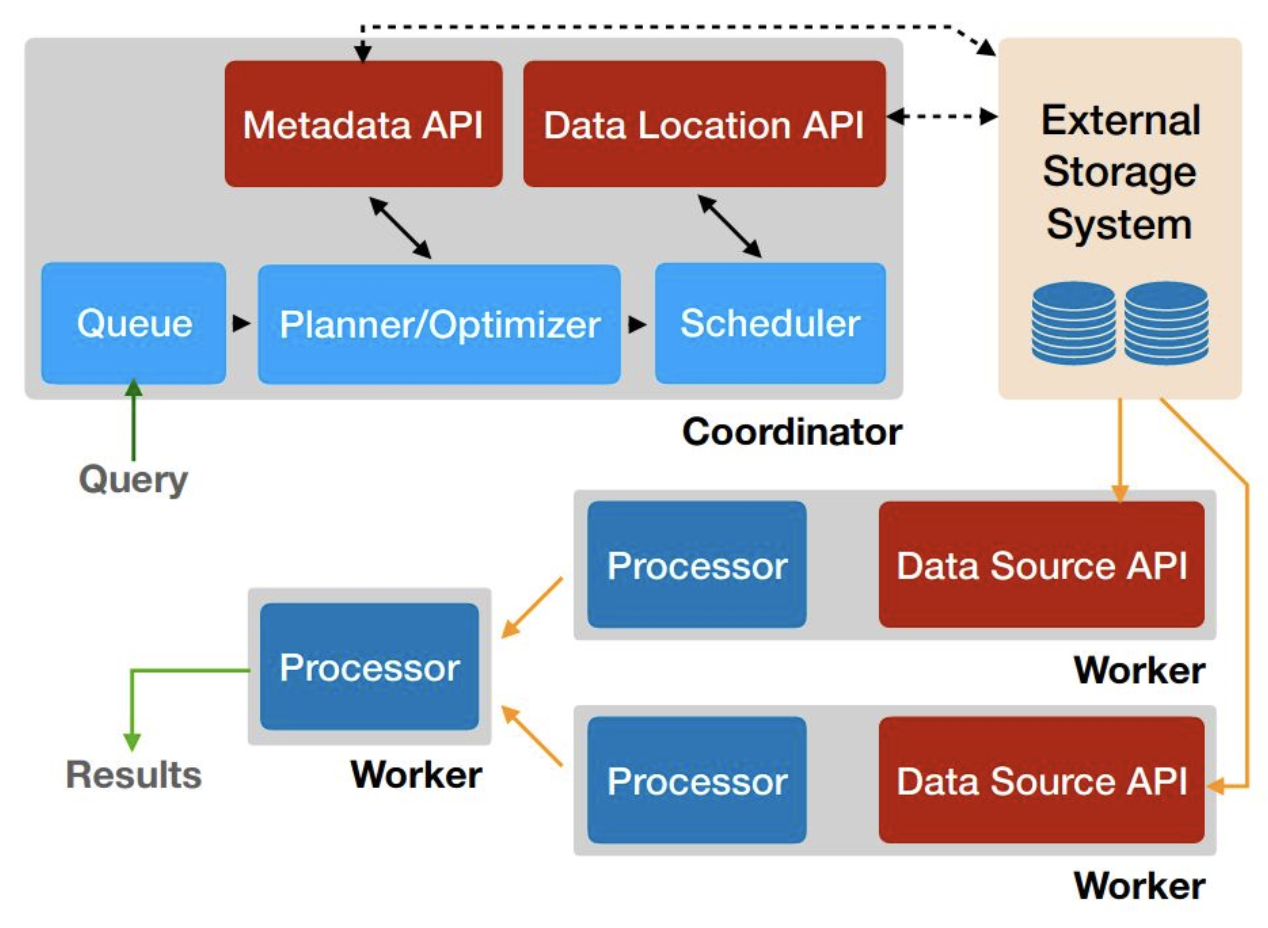
Presto Concepts
Coordinator: This is the brain of presto. It receives the query from the client, parses, plans, and manages the worker nodes. It keeps a track of activity on worker nodes and coordinates the execution of the query. It fetches the results from the worker nodes and returns the final result to the client. Additionally, Presto uses a discovery service that is running on the coordinator, where each worker can register and periodically send their heartbeat. This runs on the same HTTP server — including the same port.
Worker: Worker nodes are the nodes that execute the tasks and process data. They fetch data from connectors and exchange intermediate data with each other. HTTP is the communication between coordinators and workers, coordinators and clients, and between workers
Connector: Presto uses a connector to connect to various data sources. In the world of databases, this equates to DB drivers. Each connector needs to implement 4 SPI(Service Provider Interface)
- Metadata SPI
- Data Location SPI
- Data Statistics SPI
- Data Source SPI
Catalog: The catalog contains schemas and references to a data source via a connector.
Schema: A schema is a collection of tables. In RDBMS like PostgreSQL and MySQL, this translates to the concept of Schema or a Database.
Table: Collection of data in terms of rows, columns, and associated data types.
Statement: Statements are defined in the ANSI SQL standard, consisting of clauses, expressions, and predicates.
Query: The previous SQL statement is parsed into a query and creates a distributed query plan consisting of a series of interconnected stages that contain all of the below elements.
Stage: The execution is structured in a hierarchy of stages that resembles a tree. They model the distributed query plan but are not executed by the worker nodes.
Task: Each stage consists of a series of tasks that are distributed over the Presto worker nodes. Tasks contain one or more parallel drivers.
Split: Tasks operate on splits, which are sections of a larger data set.
Driver: Drivers work with the data and combine operators to produce output that is aggregated by a task and delivered to another task in another stage. Each driver has one input and one output.
Operator: An operator consumes, transforms, and produces data.
Exchange: Exchanges transfer data between Presto nodes for different stages in a query.
Presto Connectors
Overall there are 30+ known connectors that Presto supports. The following are a few well know connectors that Presto supports.
- BigQuery Connector
- Cassandra Connector
- Elasticsearch Connector
- Hive Connector
- JMX Connector
- Kafka Connector
- MongoDB Connector
- Oracle/MySQL/PostgreSQL Connector
- Prometheus Connector
- Redis Connector
- Redshift Connector
- Delta Lake Connector
Event Listener
One of the nice things about Presto is clean abstractions, one such clean abstraction is Event Listeners. Event Listener allows you to write custom functions that listen to events happening inside the engine. Event listeners are invoked for the following events:
- Query creation
- Query completion
- Split completion
To Create Custom Listeners we would need to do the following:
- Implement EventListener and EventListenerFactory interfaces.
- Register the plugins and deploy the plugin to Presto.
Query Optimization
PrestoDB uses two optimizers. The Rule-Based Optimizer (RBO) applies filters to remove irrelevant data and uses hash joins to avoid full cartesian joins. This includes strategies such as predicate pushdown, limit pushdown, column pruning, and decorrelation. It also uses a Cost-Based Optimizer (CBO). Here it uses statistics of the table (e.g., number of distinct values, number of null values, distributions of column data) to optimize queries and reduce I/O and network overhead. The following are ways to see available statistics and see cost-based analysis of a query
SHOW STATS FOR table_name — Approximated statistics for the named table
SHOW STATS FOR ( SELECT query ) — Approximated statistics for the query result
EXPLAIN SELECT query — Execute statement and show the distributed execution plan with the cost of each operation.
EXPLAIN ANALYZE SELECT — Execute statement and show the distributed execution plan with the cost and duration of each operation.
SQL Language and SQL Statement Syntax
We can use DDL, DML, DQL, DCL, TCL which modern databases support. The following are supported in PrestoDB
- DDL — Create, Alter, Drop, Truncate
- DML — Insert, Delete, Call
- TCL — Commit, Rollback, Start Transaction
- DQL — Select
- DCL — Grant, Revoke
It also supports the following data types
Boolean, TINYINT, SMALLINT, INTEGER, BIGINT, DOUBLE, DECIMAL, VARCHAR, CHAR, JSON, DATE, TIME, TIMESTAMP, ARRAY, MAP, IPADDRESS
An Example with JMX Connector
Java Management Extensions (JMX) gives information about the Java Virtual Machine and software running inside JVM. With the JMX connector, we can query JMX information from all nodes in a Presto cluster. JMX is actually a connector that is figured so that chosen JMX information will be periodically dumped and stored in tables (in the “jmx” catalog) which can be queried. JMX is useful for debugging and monitoring Presto metrics.
To configure the JMX connector, create catalog properties file etc/catalog/jmx.properties with the following
connector.name=jmx
JMX connector supports 2 schemas — current and history
To enable periodical dumps, define the following properties:
connector.name=jmx jmx.dump-tables=java.lang:type=Runtime,com.facebook.presto.execution.scheduler:name=NodeScheduler jmx.dump-period=10s jmx.max-entries=86400
We will use jdbc driver to connect to presto — com.facebook.presto.jdbc.PrestoDriver
the following is used to extract the JVM version of every node.
String dbUrl= “jdbc:presto://localhost:9000/catalogName/schemaName”;
Connection conn = null;Statement stmt = null;try {Class.forName(“com.facebook.presto.jdbc.PrestoDriver”);conn = DriverManager.getConnection(dbUrl, “username”, “password”);stmt = conn.createStatement();String sql = “SELECT node, vmname, vmversion from jmx.current.java.lang:type=runtime”;ResultSet res = stmt.executeQuery(sql);while (res.next()) {String node= res.getString(“node”);String vmname= res.getString(“vmname”);String vmversion= res.getString(“vmversion”);}res.close();stmt.close();conn.close();} catch (SQLException se) {se.printStackTrace();} catch (Exception e) {e.printStackTrace();} finally {try {if (stmt != null) stmt.close();} catch (SQLException sqlException) {sqlException.printStackTrace();}try {if (conn != null) conn.close();} catch (Exception e) {e.printStackTrace();}}}}
If we want to see all of the available MBeans by running SHOW TABLES, we can use SHOW TABLES FROM jmx.current
If we want to see the open and maximum file descriptor counts for each node then the following is the query — SELECT openfiledescriptorcount, maxfiledescriptorcount
FROM jmx.current.java.lang:type=operatingsystem`
Where can Presto be used?
- It can be used in Data Warehouse where data is fetched from multiple sources in TB and PB to query and process large datasets
- It can be used to run ad hoc queries from various sources through multiple connectors anytime we want and wherever the data resides
- It can be used for generating reports and dashboards as data is collected from various sources that are in multiple formats for analytics and business intelligence
- We can aggregate TBs of data from multiple data sources and run ETL queries against that data instead of using legacy batch processing systems, we can use presto to run efficient and high throughput queries
- We can query data on a data lake without the need for transformation. we can query any type of data in a data lake, including both structured and unstructured data as there are various connectors to pull from structured and unstructured sources

RELATED ARTICLES

- Engineering
- 2 min
Zeta: Pioneering Digital Transactions with Cutting-Edge Technology and Innovation
Zeta's mission is to design a transformative technology platform revolutionizing digital transactions through advanced cryptography…

Ramki Gaddipati
APAC CEO, Global CTO, Zeta

- Engineering
- 6 min
Troubleshooting Blueprint: Essential Strategies for Engineers
Zeta's expert guidelines and tips for effective troubleshooting enhance incident management and system reliability, ensuring…

- Engineering
- 5 min
Balancing Ease and Security: Zeta’s Best Practices for Secure Mobile Applications
Zeta implements robust security principles in mobile applications, balancing ease of use with stringent protection…